Jun 26, 2026
Pay for Apify Actors with x402
New
Actor
API
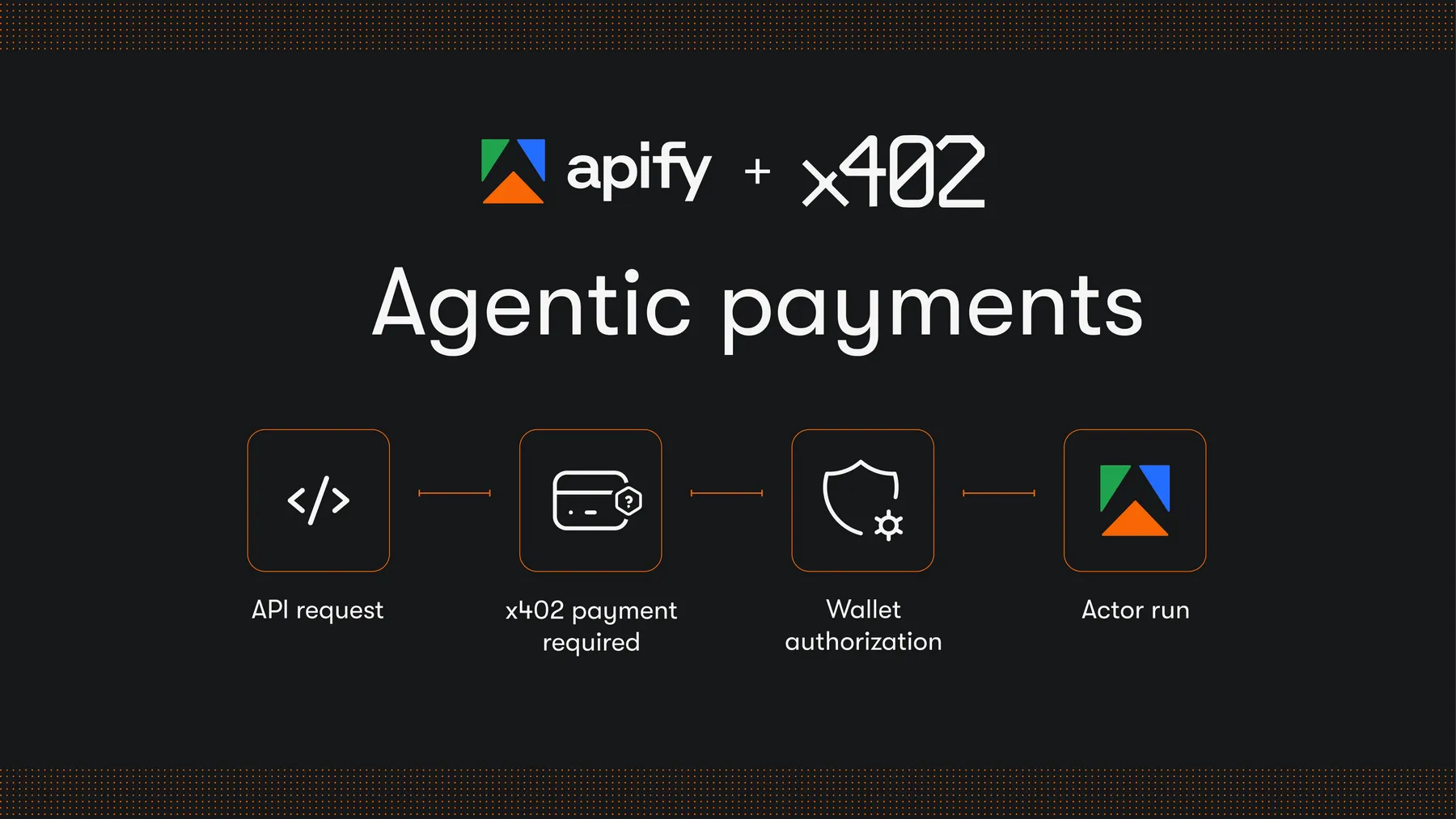 AI agents can now run and pay for eligible Apify Actors in USDC on the Base network. No Apify account, billing, or API key required. Payments use the open x402 protocol and settle at the time of request, over both Apify MCP server and the Apify API.
AI agents can now run and pay for eligible Apify Actors in USDC on the Base network. No Apify account, billing, or API key required. Payments use the open x402 protocol and settle at the time of request, over both Apify MCP server and the Apify API.
The fastest and easiest way is to use Coinbase Agentic Wallet CLI :
To get started, give this skill to your agent: apify.it/x402-awal.
If you're building Actors, you can review the eligibility criteria to make sure yours can accept agentic payments. For more information, see the docs and blog post .